AlphaGo的圍棋學習之路 從人類智慧到自我超越

AlphaGo是由Google旗下DeepMind公司開發的圍棋人工智能程序,它通過結合深度學習與強化學習技術掌握了圍棋的精髓。其學習過程分為兩個關鍵階段:
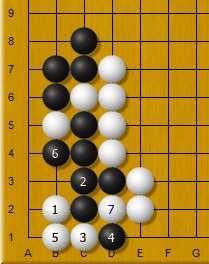
1. **向人類棋手學習**:初期,AlphaGo通過分析成千上萬盤人類頂尖棋手的對局數據,包括柯潔、李世石等大師的棋譜,從中學習圍棋的基本策略、定式與布局規律。
2. **自我博弈進化**:隨后,AlphaGo進入強化學習階段,通過與自己進行數百萬盤對弈,不斷探索新策略并優化決策。這一過程超越了人類經驗的局限,最終形成了獨特的“圍棋直覺”。
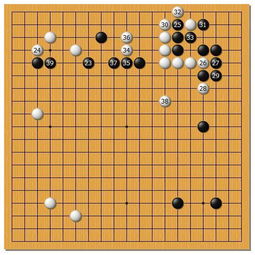
2016年,AlphaGo以4:1擊敗李世石;2017年,其升級版AlphaGo Master又以3:0完勝當時世界排名第一的柯潔。值得注意的是,后續版本AlphaGo Zero甚至完全摒棄人類數據,僅通過自我對弈就達到了更高境界。
AlphaGo的突破不僅展示了人工智能的潛力,更重新定義了圍棋的戰術邊界——它并非簡單模仿人類,而是開創了一種融合計算與直覺的新型圍棋哲學。
如若轉載,請注明出處:http://www.dayoukejigs.com/product/585.html
更新時間:2025-11-14 13:30:48